
Solving the MuJoCo HumanoidStandup Task with PPO and Stable-Baselines3
If you’ve ever tinkered with reinforcement learning (RL) in physics-based simulation environments, you’ve probably come across MuJoCo’s HumanoidStandup task.
It’s an interesting challenge — a simulated humanoid lying on the floor must figure out how to stand up and remain balanced.
In this article, I’ll walk you through how I trained an agent to solve HumanoidStandup-v5 using Proximal Policy Optimization (PPO) from Stable-Baselines3 with parallel environments and checkpointing.
Videos
The challenge
The Solution
Why Humaoid Standup?
Unlike simpler control tasks, HumanoidStandup requires:
- Coordination across many joints (over 17 degrees of freedom)
- Long-term planning — it takes many steps before the agent even begins to stand
- Stable control — once up, the agent must avoid falling.
This makes it a perfect testbed for robust RL algorithms like PPO.
Environment & Tools
We’re using:
- MuJoCo: A physics engine for accurate and efficient simulations.
- Stable-Baselines3: High-quality RL algorithms in PyTorch.
- PPO: A policy gradient method with clipped objectives for stable updates.
- VecNormalize: For normalizing observations and rewards.
- SubprocVecEnv: For running multiple environments in parallel.
Imports
This section of your script is essentially about bringing in all the libraries and tools you need before training the PPO agent in the MuJoCo HumanoidStandup environment.
Let’s break it down line by line so the purpose of each import is clear:
import osHandles file and directory operations — like creating log directories, saving model checkpoints, and checking if files exist.
import torchPyTorch is the deep learning backend for Stable-Baselines3.
Used to detect device type ('cuda' for GPU or 'cpu'), and PPO policies themselves are built using PyTorch
from stable_baselines3 import PPOImports the Proximal Policy Optimization algorithm implementation from Stable-Baselines3.
This is the core RL algorithm we’re using to train the humanoid.
from stable_baselines3.common.vec_env import DummyVecEnv, SubprocVecEnv, VecNormalizeThese are vectorized environment wrappers, which allow running multiple environments in parallel for faster and more stable training.
DummyVecEnv— runs environments sequentially in the same process (good for debugging).SubprocVecEnv— runs environments in separate processes (faster in heavy simulations like MuJoCo).VecNormalize— automatically normalizes observations (so inputs are on a consistent scale) and optionally normalizes rewards (prevents huge reward spikes from destabilizing learning).
from stable_baselines3.common.env_util import make_vec_envA helper function to easily create multiple copies of the same environment (either DummyVecEnv or SubprocVecEnv), avoiding manual looping.
from stable_baselines3.common.callbacks import EvalCallback, BaseCallbackBaseCallback — lets you write custom callbacks (e.g., save model every N steps, log custom metrics).
EvalCallback — automatically evaluates the agent periodically during training and saves the best-performing model.
from pyvirtualdisplay import Display- Creates a virtual display in environments without a GUI (like remote servers or Colab), so MuJoCo can render without needing a real monitor.
- This is often essential when running RL experiments in headless Linux environments.
Parallel Training Setup
# Start virtual display for Mujoco rendering (optional for Colab)
Display(visible=0, size=(1400, 900)).start()
# Device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
# Paths
log_dir = log_dir = "/content/drive/MyDrive/Colab Notebooks/Reinforcement_learning/Stable_Baseline/ppo_humanoid_standup_log_20_Million/"
model_path = os.path.join(log_dir, "ppo_humanoid_standup.zip")
os.makedirs(log_dir, exist_ok=True)
# Create Parallel VecNormalize Envs
n_envs = 8 # Parallel environments
env = VecNormalize(
make_vec_env("HumanoidStandup-v5", n_envs=n_envs, vec_env_cls=SubprocVecEnv),
norm_obs=True,
norm_reward=True,
clip_obs=10.
)
eval_env = VecNormalize(
make_vec_env("HumanoidStandup-v5", n_envs=1),
training=False,
norm_obs=True,
norm_reward=False
)
We detect whether a GPU ('cuda') or CPU is available with PyTorch and set our device accordingly.
We then define a log_dir to store training logs, model checkpoints, and evaluation results, creating the directory if it doesn’t exist.
For training efficiency, we set up eight parallel instances of the HumanoidStandup-v5 environment using SubprocVecEnv, which runs each environment in its own process for faster data collection.
We wrap these in VecNormalize to normalize both observations and rewards, clipping observations to a maximum of 10 for stability. Alongside the training environment, we also prepare a separate evaluation environment with identical observation normalization but without reward normalization, ensuring fair and consistent performance evaluation throughout training.
Checkpointing
# Checkpoint Callback
class CheckpointCallback(BaseCallback):
def __init__(self, save_freq, save_path, verbose=1):
super().__init__(verbose)
self.save_freq = save_freq
self.save_path = save_path
def _on_step(self) -> bool:
if self.n_calls % self.save_freq == 0:
save_file = os.path.join(self.save_path, "ppo_humanoid_standup_latest.zip")
self.model.save(save_file)
env.save(os.path.join(self.save_path, "vecnormalize_latest.pkl")) # Save normalization stats
if self.verbose > 0:
print(f"Checkpoint saved at step {self.num_timesteps} -> {save_file}")
return True
checkpoint_callback = CheckpointCallback(save_freq=50_000, save_path=log_dir)
# Evaluation Callback
eval_callback = EvalCallback(
eval_env,
best_model_save_path=log_dir,
log_path=log_dir,
eval_freq=50_000,
deterministic=True,
render=False,
n_eval_episodes=5
)
To safeguard training progress and track performance, we set up two important callbacks. First is our custom CheckpointCallback, which saves the PPO model and the environment’s normalization statistics every 50,000 steps. This ensures that even if training is interrupted, we can resume from the latest checkpoint without losing progress or breaking normalization consistency. The second is the built-in EvalCallback, which evaluates the agent every 50,000 steps on the separate evaluation environment. It records results, logs them for later analysis, and automatically saves the best-performing model based on evaluation scores. Together, these callbacks act like an insurance policy for long-running training sessions—preserving work, monitoring learning progress, and capturing the highest-quality agent along the way.
PPO Setup
#PPO Policy Config
policy_kwargs = dict(
net_arch=[512, 256, 128],
activation_fn=torch.nn.ReLU
)
# Load or Create PPO Model
if os.path.exists(model_path):
print("Loading existing model...")
model = PPO.load(model_path, env=env, device=device)
env = model.get_env()
else:
print("Creating new model...")
model = PPO(
"MlpPolicy",
env,
device=device,
verbose=1,
tensorboard_log=log_dir,
learning_rate=3e-4,
n_steps=2048,
batch_size=4096,
n_epochs=10,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
ent_coef=0.01,
policy_kwargs=policy_kwargs,
)With the environments and callbacks ready, we configure our PPO policy architecture. The policy_kwargs define a fully connected neural network with three hidden layers of sizes 512 → 256 → 128, using ReLU activations for non-linearity. This larger architecture is chosen to handle the high-dimensional observation space of the HumanoidStandup task. Before starting training, the script checks whether a previously saved model exists. If it does, we load the model and its environment to resume training from the last checkpoint. Otherwise, we create a new PPO agent with carefully tuned hyperparameters: a learning rate of 3e-4, rollout size of 2048 steps per environment, large batch size of 4096 for stable gradient estimates, 10 optimization epochs per update, discount factor gamma=0.99 for long-term rewards, GAE lambda 0.95 for advantage estimation, clip range 0.2 for stable updates, and entropy coefficient 0.01 to encourage exploration. Logging is enabled through TensorBoard for real-time monitoring. This setup ensures that the model is both expressive enough to capture complex strategies and stable enough to converge effectively.
Training and Saving
# Training
print("Starting training...")
model.learn(
total_timesteps=3_000_000, # Recommend 5M+ for good results
callback=[eval_callback, checkpoint_callback],
tb_log_name="ppo_humanoid_standup",
progress_bar=True
)
# Save Final Model & VecNormalize
model.save(model_path)
env.save(os.path.join(log_dir, "vecnormalize_final.pkl"))
print("Training completed.")With everything in place, we launch the training process. The model.learn() function runs PPO for 3 million timesteps (although 5M+ is recommended for the HumanoidStandup task to achieve strong, stable performance). During training, the EvalCallback periodically assesses the agent’s performance, while the CheckpointCallback ensures that progress is saved regularly. Logging to TensorBoard under the tag "ppo_humanoid_standup" allows us to monitor reward trends, losses, and other metrics in real time. The progress_bar=True option gives a live indication of how far the training has progressed. Once training finishes, we save the final model along with the VecNormalize statistics, which are crucial for maintaining consistent performance during testing or deployment. At this point, our PPO agent is ready to take on the HumanoidStandup-v5 challenge—rolling over, standing up, and holding its balance like a pro.
Test the model and create a video
import os
import torch
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
from stable_baselines3.common.vec_env.vec_normalize import VecNormalize
import gymnasium as gym
# ==========================
# 1. Paths
# ==========================
log_dir = "/content/drive/MyDrive/Colab Notebooks/Reinforcement_learning/Stable_Baseline/ppo_humanoid_standup_log_20_Million/"
model_path = os.path.join(log_dir, "ppo_humanoid_standup.zip")
vecnorm_path = os.path.join(log_dir, "vecnormalize_final.pkl") # Final saved stats
video_folder = "/content/h_stand_videos/"
os.makedirs(video_folder, exist_ok=True)
# ==========================
# 2. Force CPU execution
# ==========================
device = "cpu"
# ==========================
# 3. Create test environment in rgb_array mode
# ==========================
def make_env():
return gym.make("HumanoidStandup-v5", render_mode="rgb_array")
env = DummyVecEnv([make_env])
# ==========================
# 4. Load VecNormalize stats (important for PPO performance)
# ==========================
if os.path.exists(vecnorm_path):
print("Loading VecNormalize stats...")
env = VecNormalize.load(vecnorm_path, env)
env.training = False
env.norm_reward = False
else:
print("No VecNormalize stats found — running without normalization.")
# ==========================
# 5. Wrap env with video recorder
# ==========================
env = VecVideoRecorder(
env,
video_folder=video_folder,
record_video_trigger=lambda step: step == 0,
video_length=1000,
name_prefix="ppo_h_stand_eval"
)
# ==========================
# 6. Load PPO model
# ==========================
print("Loading trained model...")
model = PPO.load(model_path, env=env, device=device)
# ==========================
# 7. Run the agent
# ==========================
obs = env.reset()
rewards = 0
for _ in range(1000): # 1000 timesteps
action, _ = model.predict(obs, deterministic=True)
obs, reward, dones, _ = env.step(action)
rewards += reward
if dones.any():
break
env.close()
print(f"Video saved in {video_folder}")After training, it’s time to see our humanoid in action. For testing, we create a HumanoidStandup-v5 environment in rgb_array mode so that frames can be recorded as a video. We load the previously saved VecNormalize statistics, which is critical because PPO was trained on normalized observations and rewards—skipping this step would significantly degrade performance. The environment is then wrapped with VecVideoRecorder, which captures a 1000-step rollout and saves it as an MP4 file. We force the model to run on CPU for maximum compatibility, load our trained PPO policy, and let it play out the episode using deterministic=True for consistent behavior. As the agent runs, it executes the exact learned strategy from training: rolling over, pushing itself upright, and balancing steadily. When the episode ends or the time limit is reached, the video is stored in the specified folder, ready for playback and sharing. This final step not only verifies that training was successful but also provides a visual record of our agent’s achievement.
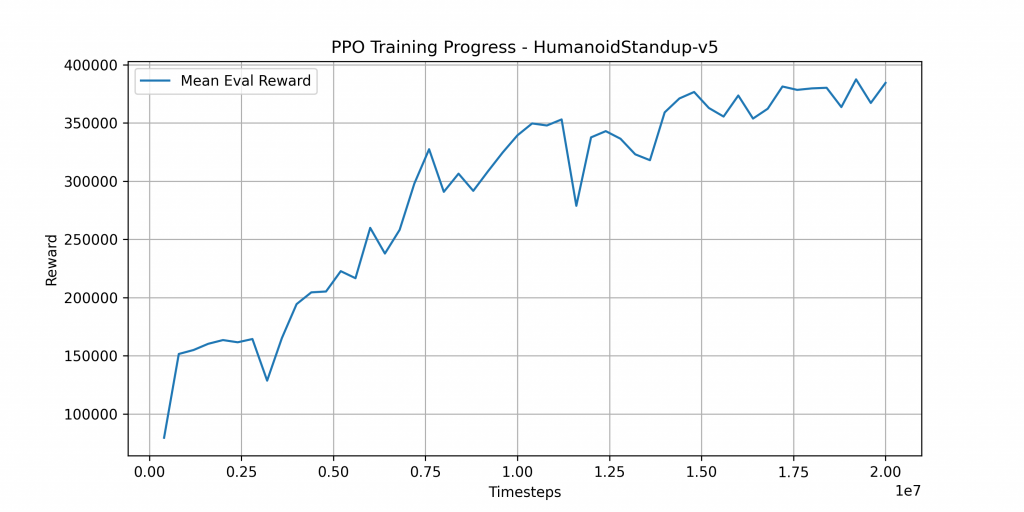
Plotting the Reward
# Plot Training Progress
import pandas as pd
import matplotlib.pyplot as plt
import os
import numpy as np
# Monitor file from EvalCallback
eval_log_file = os.path.join(log_dir, "evaluations.npz")
if os.path.exists(eval_log_file):
data = np.load(eval_log_file)
timesteps = data["timesteps"]
results = data["results"].mean(axis=1) # average reward over episodes
ep_lengths = data["ep_lengths"].mean(axis=1)
# Ensure directory exists
os.makedirs(log_dir, exist_ok=True)
# Plot Mean Eval Reward
plt.figure(figsize=(10, 5))
plt.plot(timesteps, results, label="Mean Eval Reward")
plt.xlabel("Timesteps")
plt.ylabel("Reward")
plt.title("PPO Training Progress - HumanoidStandup-v5")
plt.grid(True)
plt.legend()
plt.savefig(os.path.join(log_dir, "mean_eval_reward.png"), dpi=300)
plt.show()
print(f"Plots saved to {log_dir}")
else:
print("⚠ No evaluation log found. Make sure EvalCallback ran during training.")
Video of MuJoCo HumanoidStandup Solved
Code on Github for MuJoCo HumanoidStandup Solved using PPO
/
Lessons Learned
After millions of training steps, our PPO agent successfully learned the complex sequence of actions required to solve the HumanoidStandup-v5 challenge in MuJoCo. The humanoid starts from lying on the ground, rolls over, pushes with its arms and legs, and finally achieves a stable upright stance — all without explicit instructions. By combining parallel environments, observation/reward normalization, and periodic checkpointing, training remained stable and recoverable even across long runs.
In our tests, the trained agent consistently achieved high rewards, demonstrating robust and repeatable behavior. The visual evaluation confirmed that PPO, paired with Stable-Baselines3’s vectorized workflow, is more than capable of mastering high-dimensional continuous control tasks.
Key takeaways from this project:
- VecNormalize is critical — skipping it drastically hurts performance.
- Checkpoint early and often — crashes or Colab timeouts won’t cost you your work.
- Parallel environments speed things up — more diverse experiences lead to faster learning.
- Evaluation during training is not optional — it keeps you aware of overfitting or stagnation.
This project shows that with the right setup, teaching complex humanoid behaviors in simulation is accessible to anyone with the right tools and a bit of patience. The trained model and recorded videos are not just proof of success, but a stepping stone toward more ambitious goals — like sim-to-real transfer or even multi-skill humanoid control.