PPO Implementation in PyTorch
In this blog post, we will explore the Proximal Policy Optimization (PPO) algorithm. We’ll compare it to other deep reinforcement learning algorithms like Double Deep Q-learning and TRPO. Additionally, we’ll learn how to implement PPO using PyTorch.
An Introduction to Proximal Policy Optimization (PPO)
In the world of reinforcement learning (RL), Proximal Policy Optimization (PPO) stands out as a robust, efficient, and relatively simple algorithm. Developed by OpenAI, PPO has become a go-to method for training agents to perform complex tasks. In this post, we’ll explore how PPO works, from taking states as inputs to making actions and optimizing the network using its unique loss function.
Understanding the Basics of PPO
PPO is a type of policy gradient method. Policy gradient methods aim to directly optimize the policy—the agent’s strategy for selecting actions based on states—by adjusting its parameters to maximize the expected reward. Unlike value-based methods that learn a value function to guide actions, policy gradient methods learn a policy that directly maps states to actions.
How PPO Takes States as Input
At the core of PPO is a neural network that represents the policy πθ(a/s) and, often, another neural network for the value function Vɸ(s). Here’s how the process begins:
- State Input: The agent observes the current state of the environment, denoted as st.
- Neural Network Processing: This state is fed into the policy network, which processes the state through several layers of neurons, applying weights and activation functions to transform the input into a probability distribution over possible actions.
The policy network outputs the probabilities of taking each possible action given the current state. These probabilities are used to sample an action.
Taking Action
Once the policy network outputs a probability distribution over actions, the agent can take an action:
- Action Sampling: An action at is sampled from the policy πθ(at/st). This means that the action is chosen based on the probabilities assigned by the network.
- Environment Interaction: The chosen action is then executed in the environment, leading to a new state St+1 and a reward rt.
The agent continues to interact with the environment in this manner, collecting trajectories of states, actions, and rewards.
Training the Network
The goal of PPO is to improve the policy based on the experiences collected. Here’s how the training process works:
- Collect Data: The agent collects a batch of trajectories by interacting with the environment using the current policy.
- Compute Advantages: Using the collected data, PPO computes the advantage estimates Ȃt. The advantage function measures how much better an action is compared to the average action taken from that state. Generalized Advantage Estimation (GAE) is often used to compute these advantages, balancing bias and variance.
- Optimize the Surrogate Objective: PPO optimizes a clipped surrogate objective function to ensure stable policy updates. The objective function is:
 This objective function penalizes large updates to the policy by clipping the probability ratio
This objective function penalizes large updates to the policy by clipping the probability ratio  where θold represents the parameters of the policy before the update.
where θold represents the parameters of the policy before the update. - Update Policy and Value Function: Using gradient descent, the policy and value function networks are updated to minimize the combined loss function:
 Here, LVF(θ) is the loss for the value function (typically the squared error between the predicted and actual returns), and H(πθ) is an entropy bonus to encourage exploration. The coefficients c1 and c2 balance these different components of the loss function.
Here, LVF(θ) is the loss for the value function (typically the squared error between the predicted and actual returns), and H(πθ) is an entropy bonus to encourage exploration. The coefficients c1 and c2 balance these different components of the loss function.
Learning
Through repeated cycles of interaction with the environment, data collection, and policy optimization, the PPO algorithm gradually improves the policy. The clipped surrogate objective ensures that policy updates are conservative, preventing large, destabilizing changes and promoting stable learning.
Proximal Policy Optimization has proven to be a powerful algorithm for training agents in a variety of challenging environments. Its blend of simplicity, efficiency, and stability makes it a preferred choice in the RL community. By carefully managing the policy updates with a clipped surrogate objective and balancing multiple loss components, PPO achieves impressive performance in many tasks.
Comparing With Double DQN and TRPO
Proximal Policy Optimization (PPO) addressed several issues that were present with earlier reinforcement learning algorithms like Double Deep Q-Networks (Double DQN) and Trust Region Policy Optimization (TRPO). Here are some of the key problems and how PPO addressed them:
- High Variance in Policy Gradient Methods (TRPO issue):
- Problem: Policy gradient methods like TRPO often suffer from high variance, which can make training unstable and slow.
- Solution by PPO: PPO uses a clipped objective function that constrains the policy update to prevent large policy changes. This reduces variance and stabilizes training, making it more robust.
- Difficulty in Ensuring Policy Improvement (TRPO issue):
- Problem: TRPO ensures that the new policy is at least as good as the old policy via a constraint, but this constraint can be hard to enforce without negatively affecting the learning process.
- Solution by PPO: PPO simplifies the optimization objective by directly optimizing a surrogate objective that includes a clipping mechanism. This ensures policy improvement without the need for complex constraints, thereby improving ease of implementation and stability.
- Overestimation Bias (Double DQN issue):
- Problem: Double DQN was introduced to mitigate overestimation bias in Q-learning, but it can still be present in certain scenarios.
- Solution by PPO: PPO operates directly in policy space rather than value space, focusing on optimizing the policy directly without relying on Q-values. This approach avoids potential issues related to overestimation bias.
- Sample Efficiency and Exploration (Both Double DQN and TRPO):
- Problem: Both Double DQN and TRPO may struggle with sample efficiency and exploration, especially in complex environments.
- Solution by PPO: PPO uses an advantage function to estimate the advantage of each action, which helps in more efficient exploration and utilization of collected data. Additionally, the clipped surrogate objective in PPO ensures that the policy updates are not too aggressive, which can also aid in stable exploration.
In essence, PPO addresses these issues by combining insights from both policy gradient and value-based methods while introducing mechanisms like the clipped surrogate objective to improve stability, sample efficiency, and overall performance in reinforcement learning tasks.
Implementing Proximal Policy Optimization (PPO) with PyTorch: A Step-by-Step Guide
Importing Required Libraries
import gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
from collections import deque
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import randomgym: Provides environments for training the agent.torchandtorch.nn: Used for building and training neural networks.torch.optim: Provides optimization algorithms.torch.distributions: Contains probability distributions used in policy sampling.collections.deque: A double-ended queue to store experience tuples.numpy,pandas,seaborn,matplotlib, andrandom: Various utilities for data manipulation and visualization.
ActorCritic Class
The ActorCritic class defines a neural network with shared hidden layers for both the policy and value functions. The policy function (pi) outputs action logits, which are used to sample actions from a categorical distribution. The value function (v) outputs a single scalar value, representing the estimated value of the given state.
# Define the ActorCritic class
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim,hidden_dim=128):
super(ActorCritic, self).__init__()
self.fc1 = nn.Linear(state_dim,hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_pi = nn.Linear(hidden_dim, action_dim)
self.fc_v = nn.Linear(hidden_dim, 1)
self.optimizer = optim.Adam(self.parameters(), lr=0.002)
def pi(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc_pi(x)
return Categorical(logits=x)
def v(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
v = self.fc_v(x)
return v__init__
def __init__(self, state_dim, action_dim, hidden_dim=128):
super(ActorCritic, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_pi = nn.Linear(hidden_dim, action_dim)
self.fc_v = nn.Linear(hidden_dim, 1)
self.optimizer = optim.Adam(self.parameters(), lr=0.002)
- Parameters:
state_dim: The dimensionality of the state space.action_dim: The dimensionality of the action space.hidden_dim: The number of units in the hidden layers (default is 128).
- Layers:
self.fc1: The first fully connected layer that maps the input state to a hidden representation.self.fc2: The second fully connected layer that further processes the hidden representation.self.fc_pi: The fully connected layer that outputs action logits, used by the policy function.self.fc_v: The fully connected layer that outputs a single value, used by the value function.
- Optimizer:
self.optimizer: An Adam optimizer with a learning rate of 0.002, used to update the network parameters.
Policy Function
def pi(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc_pi(x)
return Categorical(logits=x)
- Input:
x: The input state tensor.
- Processing:
- The input state tensor
xis passed through the first fully connected layer (self.fc1), followed by atanhactivation function. - The resulting tensor is then passed through the second fully connected layer (
self.fc2), followed by anothertanhactivation function.
- The input state tensor
- Output:
- The processed tensor is then passed through the final fully connected layer (
self.fc_pi) to produce logits for the action distribution. - These logits are used to create a
Categoricaldistribution object, representing the policy’s action probabilities.
- The processed tensor is then passed through the final fully connected layer (
Value Function
def v(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
v = self.fc_v(x)
return v- Input:
x: The input state tensor.
- Processing:
- Similar to the policy function, the input state tensor
xis passed through the first fully connected layer (self.fc1), followed by atanhactivation function. - The resulting tensor is then passed through the second fully connected layer (
self.fc2), followed by anothertanhactivation function.
- Similar to the policy function, the input state tensor
- Output:
- The processed tensor is then passed through the final fully connected layer (
self.fc_v) to produce a single scalar value, representing the estimated value of the input state.
- The processed tensor is then passed through the final fully connected layer (
Key Points:
- Shared Layers: The initial layers (
fc1andfc2) are shared between the policy and value functions, allowing the network to learn a common representation of the state space. - Separate Output Layers: The final layers (
fc_piandfc_v) are separate for the policy and value functions, enabling the network to produce distinct outputs for each function. - Optimization: The network uses the Adam optimizer to update its parameters based on the loss computed during training.
This architecture allows the PPO agent to efficiently learn both the policy and value functions, enabling stable and effective training.
PPOAgent Class
The PPOAgent class encapsulates the PPO algorithm, handling policy updates, memory management, and interaction with the environment.
__init__
def __init__(self, state_dim, action_dim, buffer_size, gamma, K_epochs, eps_clip,hidden_dim=128):
self.policy = ActorCritic(state_dim, action_dim,hidden_dim)
self.policy_old = ActorCritic(state_dim, action_dim,hidden_dim)
self.policy_old.load_state_dict(self.policy.state_dict())
self.optimizer = self.policy.optimizer
self.MseLoss = nn.MSELoss()
self.memory = deque(maxlen=buffer_size)
self.gamma = gamma
self.K_epochs = K_epochs
self.eps_clip = eps_clip
self.rewards = []The __init__ method sets up the PPO agent with the necessary components:
- Policy Networks: Initializes the current and old policy networks using the
ActorCriticclass. - Optimizer: References the optimizer from the current policy network.
- Loss Function: Initializes the mean squared error loss function for value updates.
- Memory Buffer: Sets up a deque to store experience tuples.
- Hyperparameters: Configures the discount factor, number of update epochs, and clipping parameter.
- Reward Storage: Initializes an empty list to store episode rewards.
This initialization prepares the agent to interact with the environment, collect experiences, and update its policy based on the PPO algorithm.
update
The update method in the PPOAgent class is responsible for updating the policy network using the experiences stored in the memory buffer. This process is the core of the Proximal Policy Optimization (PPO) algorithm. Let’s break down the method step by step.
Step 1: Extract Experiences from Memory
states, actions, logprobs, rewards, is_terminals = zip(*self.memory)Step 2: Compute Discounted Rewards
discounted_rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(rewards), reversed(is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
discounted_rewards.insert(0, discounted_reward)
- This loop computes the discounted rewards. It starts from the last reward and works backwards.
- If the current step is terminal (
is_terminalisTrue), the discounted reward is reset to 0. - Otherwise, the discounted reward is updated using the formula:
discounted_reward = reward + (self.gamma * discounted_reward). - The computed discounted reward is then inserted at the beginning of the
discounted_rewardslist.
Step 3: Normalize Discounted Rewards
discounted_rewards = torch.tensor(discounted_rewards, dtype=torch.float32)
discounted_rewards = (discounted_rewards - discounted_rewards.mean()) / (discounted_rewards.std() + 1e-7)
- The discounted rewards are converted to a PyTorch tensor.
- The rewards are normalized to have zero mean and unit variance to improve the stability of the training process.
Step 4: Prepare Old States, Actions, and Log Probabilities
old_states = torch.squeeze(torch.stack(states).detach())
old_actions = torch.squeeze(torch.stack(actions).detach())
old_logprobs = torch.squeeze(torch.stack(logprobs).detach())- The lists of states, actions, and log probabilities are stacked into tensors and detached from the computation graph to prevent gradients from flowing through them.
torch.squeezeis used to remove any singleton dimensions.
Step 5: Perform Multiple Epochs of Updates
for _ in range(self.K_epochs):
logprobs, state_values, dist_entropy = self.evaluate(old_states, old_actions)
ratios = torch.exp(logprobs - old_logprobs.detach())
advantages = discounted_rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5 * self.MseLoss(state_values, discounted_rewards) - 0.01 * dist_entropy
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
- For each epoch:
- The method evaluates the policy by calling
self.evaluatewith the old states and actions. This returns the log probabilities, state values, and distribution entropy. - The probability ratios between the new and old policies are computed as
ratios = torch.exp(logprobs - old_logprobs.detach()). - The advantages are computed as the difference between the discounted rewards and the state values.
- Two surrogate loss terms (
surr1andsurr2) are computed.surr2uses a clipped ratio to prevent large updates. - The total loss is computed as the minimum of the surrogate losses, plus a value loss term and an entropy regularization term.
- The optimizer is used to backpropagate the loss and update the policy network’s parameters.
- The method evaluates the policy by calling
Step 6: Update the Old Policy
self.policy_old.load_state_dict(self.policy.state_dict())
- Finally, the old policy network’s weights are updated to match the current policy network’s weights.
Summary
The update method implements the PPO algorithm’s core update step. It involves:
- Extracting and organizing experiences from the memory buffer.
- Computing and normalizing discounted rewards.
- Preparing tensors for old states, actions, and log probabilities.
- Performing multiple epochs of policy updates using the PPO objective function.
- Updating the old policy network to match the current policy network after the updates.
This method ensures that the policy is updated in a stable manner, improving the agent’s performance while maintaining a balance between exploration and exploitation.
evaluate
def evaluate(self, state, action):
state_value = self.policy.v(state)
dist = self.policy.pi(state)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
return action_logprobs, torch.squeeze(state_value), dist_entropy
The evaluate method performs the following tasks:
- State Value Computation: Computes the value of each state using the value function of the policy network.
- Action Distribution Computation: Computes the logits for the action distribution using the policy function of the policy network and creates a
Categoricaldistribution object. - Log Probabilities Computation: Computes the log probabilities of the given actions under the current policy distribution.
- Entropy Computation: Computes the entropy of the action distribution, providing a measure of the policy’s uncertainty.
These computed values are crucial for the PPO update process. The log probabilities are used to compute the probability ratios, the state values are used to compute the advantages, and the entropy is used as a regularization term to encourage exploration.
train
The train method in the PPOAgent class is responsible for training the agent using the PPO algorithm. It interacts with the environment, collects experiences, and updates the policy. Let’s break down the method step by step
Step 1: Initialize Training Loop
for episode in range(1, max_episodes + 1):- This loop iterates over the specified number of episodes (
max_episodes). Each iteration represents one training episode.
Step 2: Reset Environment and Initialize Variables
total_reward = 0
state = env.reset()
state = self.normalize_state(state)
done = Falsetotal_reward: Initializes the total reward for the current episode to 0.state: Resets the environment to get the initial state and normalizes it usingself.normalize_state.done: Initializes thedoneflag toFalseto indicate that the episode is not yet finished.
Step 3: Interact with Environment Until Episode Ends
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
dist = self.policy_old.pi(state_tensor)
action = dist.sample()
next_state, reward, done, _ = env.step(action.item())
next_state = self.normalize_state(next_state)
self.memory.append((state_tensor, action, dist.log_prob(action), reward, done))
state = next_state
total_reward += reward
if done:
print(f"Episode: {episode} Reward: {total_reward}")
break
- This loop continues until the
doneflag becomesTrue. state_tensor: Converts the current state to a PyTorch tensor and adds a batch dimension usingunsqueeze(0).dist: Uses the old policy (self.policy_old) to get the action distribution for the current state.action: Samples an action from the distribution.next_state, reward, done, _: Steps the environment using the sampled action to get the next state, reward, done flag, and any additional info (ignored).next_state: Normalizes the next state.self.memory.append(...): Appends the current experience (state tensor, action, log probability of the action, reward, done flag) to the memory buffer.state: Updates the current state to the next state.total_reward: Accumulates the reward received.- If the episode is done, it prints the episode number and the total reward, then breaks the loop.
Step 4: Update Policy
self.update()
self.memory.clear()
self.rewards.append(total_reward)self.update(): Calls theupdatemethod to update the policy using the experiences stored in the memory buffer.self.memory.clear(): Clears the memory buffer after updating the policy.self.rewards.append(total_reward): Appends the total reward for the episode to theself.rewardslist.
Step 5: Early Stopping and Checkpoint Saving
if early_stopping and early_stopping(self.rewards):
print("Early stopping criterion met")
if checkpoint_path:
self.save(checkpoint_path)
break- If an
early_stoppingfunction is provided and it returnsTruewhen called withself.rewards, it indicates that the early stopping criterion has been met. - It prints a message indicating early stopping.
- If a
checkpoint_pathis provided, it saves the model to the specified path. - It breaks the outer loop to stop training.
Summary
The train method implements the main training loop for the PPO agent. It performs the following tasks:
- Initialize Training Loop: Iterates over the specified number of episodes.
- Reset Environment and Initialize Variables: Resets the environment and initializes variables for each episode.
- Interact with Environment Until Episode Ends: Collects experiences by interacting with the environment and stores them in the memory buffer.
- Update Policy: Updates the policy using the collected experiences and clears the memory buffer.
- Early Stopping and Checkpoint Saving: Checks for early stopping criteria and saves the model if necessary.
- Close Environment: Closes the environment after training is complete.
This method orchestrates the entire training process, ensuring that the agent interacts with the environment, learns from its experiences, and updates its policy accordingly.
save
This method saves the current policy network’s state dictionary to a file for later use.
def save(self, checkpoint_path):
torch.save(self.policy.state_dict(), checkpoint_path)
print(f"Model saved to {checkpoint_path}")
load
This method loads the policy network’s state dictionary from a file and synchronizes the old policy network with the current policy network.
def load(self, checkpoint_path):
self.policy.load_state_dict(torch.load(checkpoint_path))
self.policy_old.load_state_dict(self.policy.state_dict())
print(f"Model loaded from {checkpoint_path}")
normalize_state
This method normalizes a given state to have zero mean and unit variance. Normalization helps in stabilizing the training process and improving the performance of the neural network.
def normalize_state(self, state):
return (state - np.mean(state)) / (np.std(state) + 1e-8)
plot
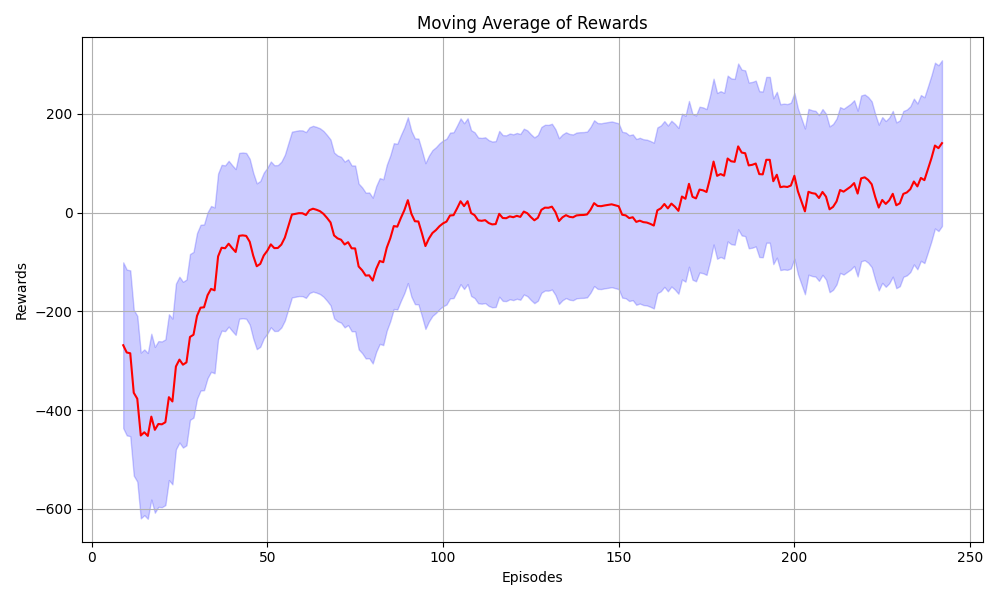
The plot method effectively visualizes the agent’s training progress by showing the moving average of rewards over episodes. It provides insights into how the agent’s performance evolves during training, with shaded areas indicating the variability around the average reward values. This kind of visualization is crucial for understanding and monitoring reinforcement learning algorithms like PPO.
def plot(self):
data = self.rewards
# Calculate the moving average
window_size = 10
moving_avg = pd.Series(data).rolling(window=window_size).mean()
# Plotting
plt.figure(figsize=(10, 6))
# Plot the moving average line
sns.lineplot(data=moving_avg, color='red')
# Shade the area around the moving average line to represent the range of values
plt.fill_between(range(len(moving_avg)),
moving_avg - np.std(data),
moving_avg + np.std(data),
color='blue', alpha=0.2)
plt.xlabel('Episodes')
plt.ylabel('Rewards')
plt.title('Moving Average of Rewards')
plt.grid(True)
# Adjust layout to prevent overlapping elements
plt.tight_layout()
# Save the plot as a PNG file
plt.savefig('Episode_rewards.png')
# Show the plot
plt.show()
Train the PPO Agent
from ppo import ActorCritic, PPOAgent
import random
import gym
import torch
import numpy as np
# Set seed for reproducibility
seed = 42
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
# Parameters
state_dim = 8
action_dim = 4
buffer_size = 5000
gamma = 0.99
K_epochs = 4
eps_clip = 0.2
max_episodes = 1500
checkpoint_path='lunar_ppo.pth'
# Instantiate the environment and the PPO agent
env = gym.make('LunarLander-v2')
env.seed(seed)
ppo = PPOAgent(state_dim, action_dim, buffer_size, gamma, K_epochs, eps_clip,hidden_dim=128)
def early_stopping(rewards, threshold=1000, window=5):
if len(rewards) >= window and sum(rewards[-window:]) > threshold:
return True
return False
ppo.train(env, max_episodes=1000, early_stopping=early_stopping, checkpoint_path='ppo_checkpoint.pth')
After training we plotted the rewards.