Pandas

DataFrame in Pandas
A data frame is a two-dimensional tabular labeled data structure with columns of potentially different types. A data frame can be created from numerous data collections such as the following:
- A 1D ndarray, list, dict, or series
- 2D Numpy ndarray
- Structured or record ndarray
- A series
- Another data frame
A data frame has arguments, which are an index (row labels) and columns (column labels).
Creating Dataframe from dictionary of series
#import necessary library
import pandas as pd
#First Series
Maths = pd.Series([10,20,30,40,50],index=['Arima','Pluto','Neptune','Zahir','Javed'])
#Second Series
Japanese = pd.Series([20,50,80,12],index=['Arima','Pluto','Zahir','Javed'])
#Dictionary of Series
Marks = {'Maths':Maths,'Japanese':Japanese}
#Dataframe from series
df = pd.DataFrame(Marks)
#Printing Dataframe
df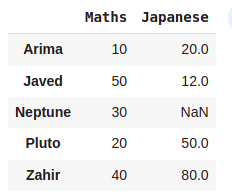
#Set index for the DataFrame
pd.DataFrame(Marks,index=['Javed','Arima','Pluto'])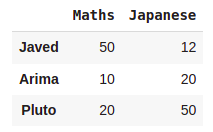
#Control the labels appearence of the DataFrame
pd.DataFrame(Marks,index=['Javed','Arima','Pluto'],columns=['Japanese','Maths'])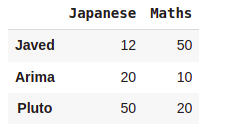
Creating DataFrames from a Dict of Ndarrays/Lists
#Without index
ndarrdict = {'One':[1,2,3,4],'Two':[2,4,6,8],'Three':[3,6,9,12]}
pd.DataFrame(ndarrdict)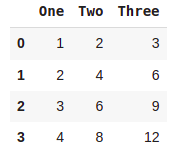
#Assign index
pd.DataFrame(ndarrdict,index=['a','b','c','e'])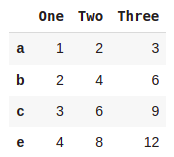
Creating Data Frames from a Structured or Record Array
import pandas as pd
import numpy as np
#creates a data frame by first specifying the data types of each
#column and then the values of each row. ('A', 'i4') determines the
#column label and its data type as integers, ('B', 'f4') determines the
#label as B and the data type as float, and finally ('C', 'a10') assigns the
#label C and data type as a string with a maximum of ten characters.
data = np.zeros((2,),dtype=[('A','i4'),
('B','f4'),
('C','a10')])
data[:] = [(1,2.,'Hello'),(2,3.3,'World')]
pd.DataFrame(data)
pd.DataFrame(data, index=['First', 'Second'])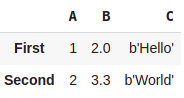
pd.DataFrame(data, columns=['C', 'A', 'B'])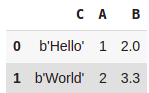
Creating Data Frames from a List of Dictionaries
data2 = [{'A': 1, 'B': 2,'C':50}, {'A': 5, 'B': 10, 'C': 20}]
pd.DataFrame(data2)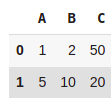
pd.DataFrame(data2, index=['First', 'Second'])
pd.DataFrame(data2, columns=['A', 'B'])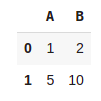
pd.DataFrame(data2, columns=['C', 'B'])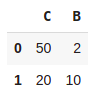
Creating Data Frames from a Dict of Tuples
dictionary = {'Maths':(1,2,3,5),'Japanese':(55,22,66,99),'Virology':(98,56,23,78)}
pd.DataFrame(dictionary)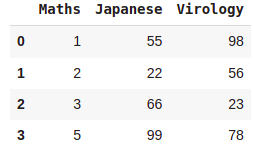
pd.DataFrame(dictionary,index=['Roll_1','Roll_2','Roll_3','Roll_4'])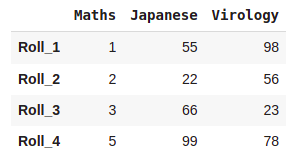
Creating DataFrame from list of tuples
marks = [(1,2,3,5),(55,22,66,99),(98,56,23,78)]
pd.DataFrame(marks)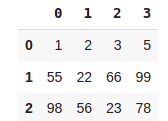
pd.DataFrame(marks,columns=['A', 'B', 'C','D'])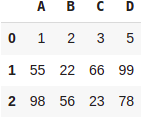
pd.DataFrame(marks,columns=['A', 'B', 'C','D'],index=['AA','BB','CC'])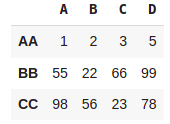
Selecting, Adding, and Deleting Data Frame Columns
expense = {'Food':[50,20,63,98],'Travel':[55,98,78,45]}
df = pd.DataFrame(expense)
df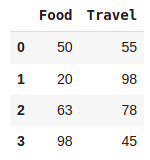
df['Total'] = df['Food']+df['Travel']
df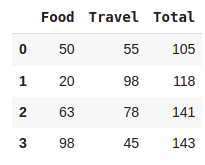
#using condition
df['Flag'] = df['Total'] > 110
df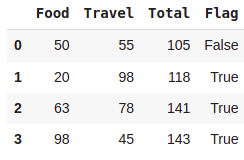
#Adding a Column Using a Scalar and Assigning to a Data Frame
df['Filler'] = 'HCT'
df['Slic'] = df['Food'][:2]
df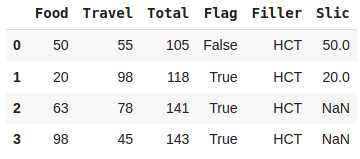
#Delete Columns
del df['Filler']
df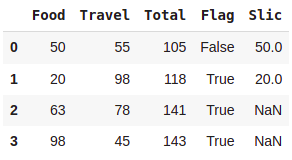
Flag = df.pop('Flag')
df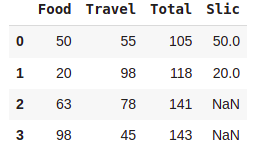
df.insert(0,'Education',[52,26,89,74])
df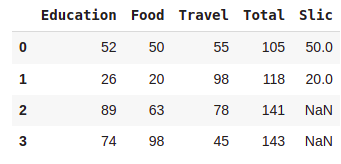
#Assigning New Columns in Method Chains
df = pd.DataFrame({'Maths':[1,25,56],'Japanese':[88,96,54]})
df = df.assign(Total=lambda x : x['Maths']+x['Japanese'])
df = df.assign(Flaf = lambda x:x['Maths']>x['Japanese'])
df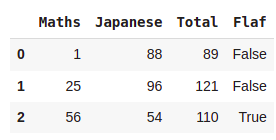
df = df.assign(Sq = lambda x:x['Maths']*2)
df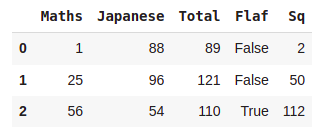
Indexing and Selecting Data Frames
df = pd.DataFrame({'Maths':[1,25,56],'Japanese':[88,96,54],
'Music':[1,15,89],'Virology':[89,57,56]})
df
df['Maths']
df.iloc[2]
df[1:]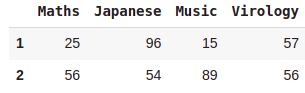
df[df['Maths']>10]
#Operation on Dataframes
df1 = pd.DataFrame({"A":[1,2,3],"B":[4,7,8],"C":[9,5,8]})
df2 = pd.DataFrame({"A":[111,2,33],"B":[46,7,68],"C":[69,5,98]})
df1
df2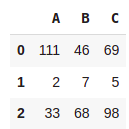
df1+df2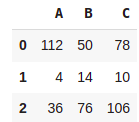
df1-df2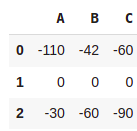
df2-df1.iloc[1]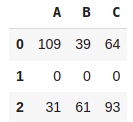
df2*2+1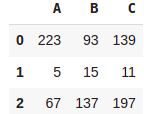
Transposing a DataFrame
df = pd.DataFrame({'Maths':[1,25,56],'Japanese':[88,96,54],
'Music':[1,15,89],'Virology':[89,57,56]})
df
df.T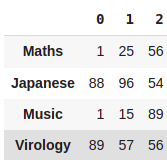
DataFrame interoperability with numpy functions
import pandas as pd
import numpy as np
df = pd.DataFrame({'Maths':[1,25,56],'Japanese':[88,96,54],
'Music':[1,15,89],'Virology':[89,57,56]})
df.T.dot(df)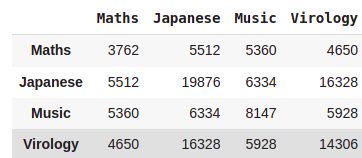
ponru
0