Pandas

Data Gathering and Cleaning
Checking and Handling Missing Values
#Creating a Data Frame Including NaN
import pandas as pd
import numpy as np
dataset = pd.DataFrame(np.random.randn(5,3),index=['a','c','e','g','h'],
columns=['Stock1','Stock2','Stock3'])
dataset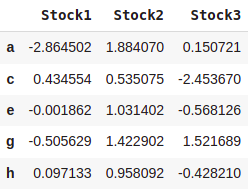
#Checking empty values for Stock1
dataset['Stock1'].isnull()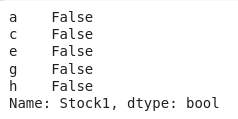
dataset = dataset.reindex(['a','b','c','d','e'])
dataset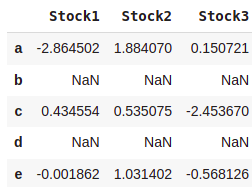
#Checking empty values for Stock1
dataset['Stock1'].isnull()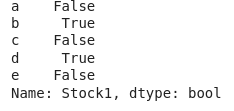
#Replacing NaN with a Scalar Value
dataset.fillna(0)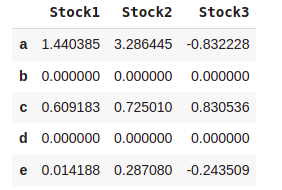
#Fill missing values forward
dataset.fillna(method='pad')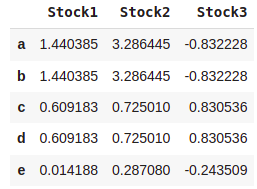
#Dropping all NaN rows
dataset.dropna()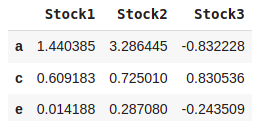
#Using the replace() function
dataset.replace(np.nan,0)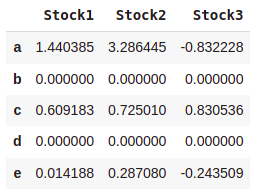
Reading and Cleaning CSV data
import pandas as pd
path = '.../Sales.xlsx'
df = pd.read_excel(path)
df.head()
#Reading nrows
df = pd.read_excel(path,nrows=4)
df
#Reading column no: 0 1 6
df = pd.read_excel(path,nrows=4,usecols=[0,1,6])
df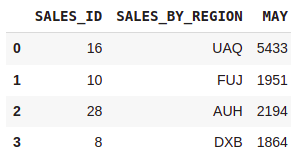
#Reading columns definded by their names
df = pd.read_excel(path,nrows=4,usecols=['SALES_ID','SALES_BY_REGION','MAY','JUNE'])
df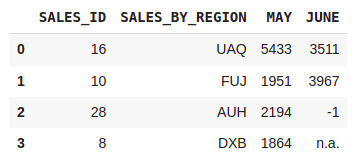
#Renaming Column Labels
#set inplace=True to commit these changes to the original data set
df = pd.read_excel(path,nrows=20)
df.rename(columns={"SALES_ID":'ID',"SALES_BY_REGION":'REGION'},inplace=True)
df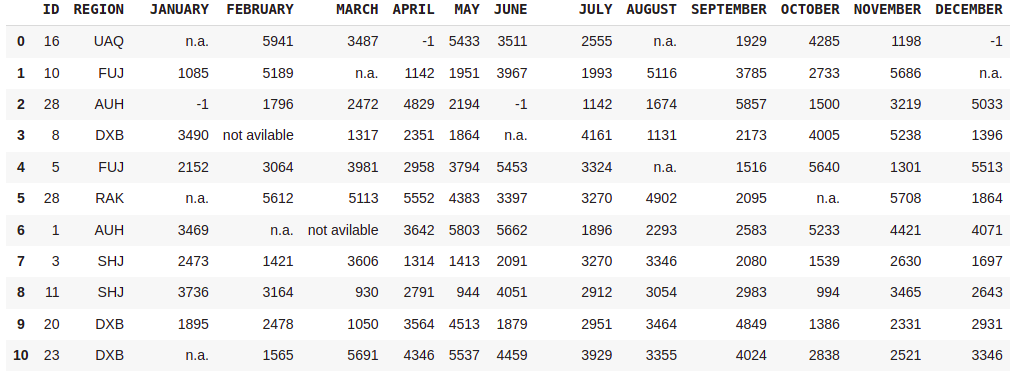
#Finding Unique values in columns
df['JANUARY'].unique()
#Automatically replacing matched cases with NaN
df = pd.read_excel(path,nrows=10,na_values=["n.a.","not avilable"])
mydata = df.head(10)
mydata
#Automatically replacing matched cases with NaN
df = pd.read_excel(path,nrows=10,na_values=["n.a.","not avilable",-1])
mydata = df.head(10)
mydata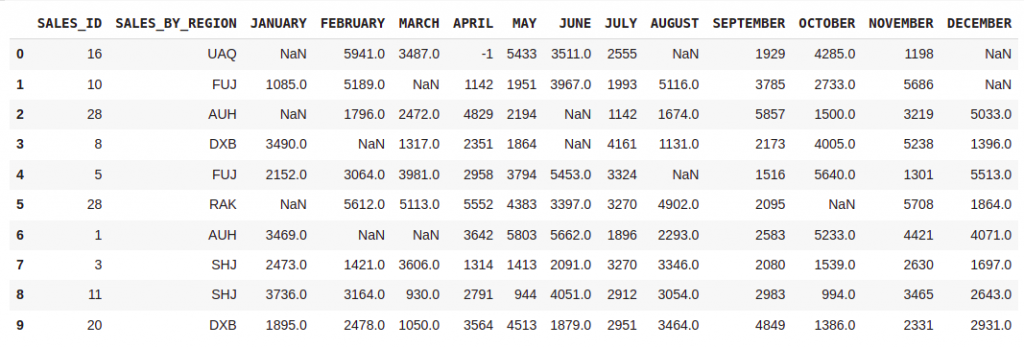
df = pd.read_excel(path,nrows=10,na_values={"SALES_BY_REGION":["n.a.","not avilabl",-1],
"JANUARY":["n.a.","not avilable",-1],
"FEBRUARY":["n.a.","not avilable",-1]})
df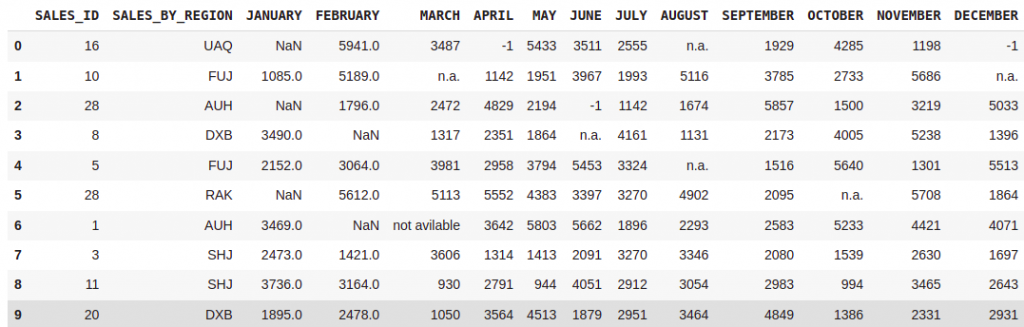
Using functions to clean data
#This functions cleans numerical values and reset all NaN values to 0
def CleanData_Sales(cell):
if(cell=='n.a.' or cell==-1 or cell=="not avilable"):
return 0
return cell#This function clean string values and reset all NaN values to Abu Dhabi
def CleanData_Region(cell):
if(cell=='n.a.' or cell=="-1" or cell=="not avilable"):
return 'AbuDhabi'
return celldf = pd.read_excel(path,nrows=10,converters={
"SALES_BY_REGION":CleanData_Region,
"JANUARY":CleanData_Sales,
"FEBRUARY":CleanData_Sales,
"FEBRUARY":CleanData_Sales,
"MARCH":CleanData_Sales,
"APRIL":CleanData_Sales,
"JUNE":CleanData_Sales,
})
df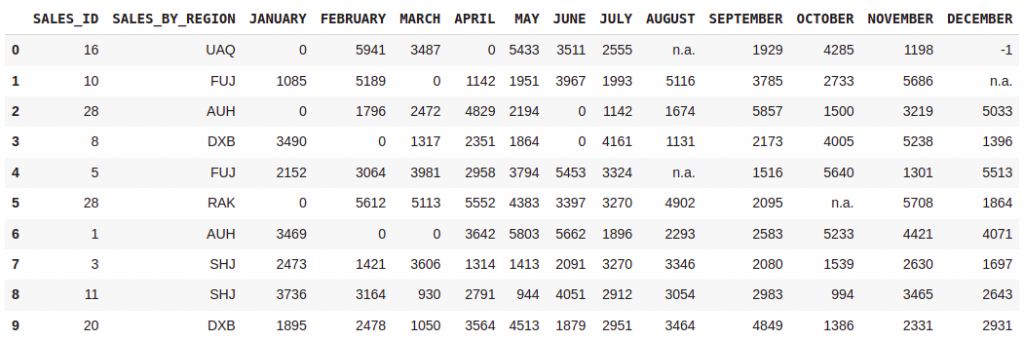
Merging and Integrating Data
Data for following section
path1 = ".../Data/1. Export1_Columns.csv"
path2 = ".../Data/1. Export2_Columns.csv"
a = pd.read_csv(path1)
b = pd.read_csv(path2)#Dropping columns 2009, 2012, 2013 and 2014
b.drop('2014',axis=1,inplace=True)
columns = ['2013','2012']
b.drop(columns,inplace=True,axis=1)
b.head()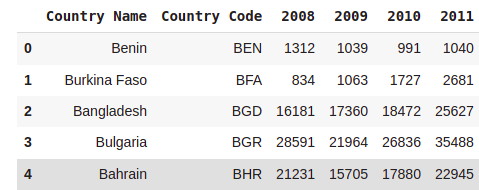
#Merging Two Data Sets
mergedDataSet = a.merge(b,on="Country Name")
mergedDataSet.head()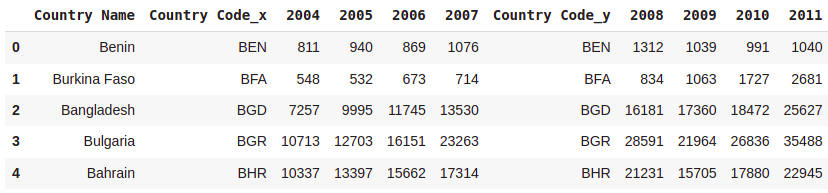
dataX = a.merge(b)
dataX.head()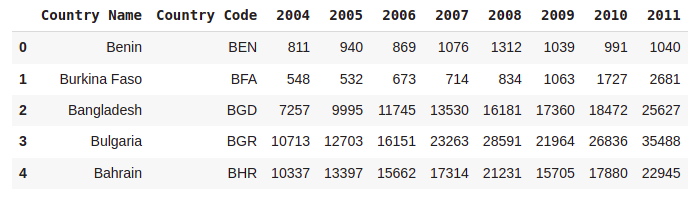
#Row Union of Two Data Sets
Data1 = a.head()
Data1 = Data1.reset_index()
Data1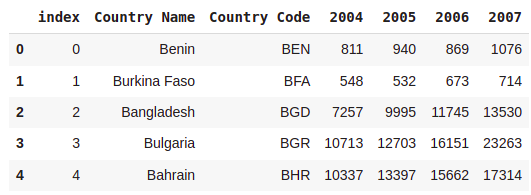
Data2 = a.tail()
Data2 = Data2.reset_index()
Data2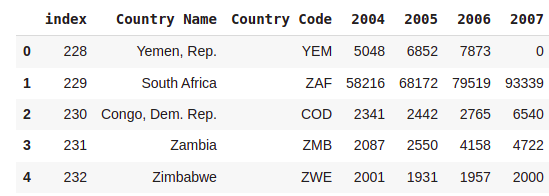
#Stack the dataframes on top of each other
VerticalStack = pd.concat((Data1,Data2),axis=0)
VerticalStack
ponru
0