
Azure MLOps for Beginners: Train, Deploy and Serve a GRU forecasting model.
Azure MLOps for Begineers is two part tutorial, where we will learn to create a fully operational pipeline using AzureML, GRU deep learning and Flask, enabling us to go from raw stock data to production ready forecasting – all in the Azure.
In this first part, we will fetch data, train the GRU model on Azure, register the model and deploy the model as a REST endpoint.
The Setup
Create a directory in your local machine along with virtual python environment.
mkdir Azure_GRU
cd Azure_GRU
python3 -m venv venv
source venv/bin/activateLaunch the Azure Machine Learning studio. After launching, click on top right. You will see the basic information: your resource group, subscription id etc. along with the link to download config file. Download the config file and move it the your current working folder in your local setup.
The Files
helper.py
Create a helper.py file in the same folder. This file will contain all the necessary functions to get the data from API and convert it to dataframe, convert the data from dataframe to a specific shape suitable for training, a function to normalize data and a function to train and evaluate model. This file also contains a Class to define GRU model.
import pandas as pd
from datetime import datetime, timedelta
# 4. Split into train/test
from sklearn.model_selection import train_test_split
def custom_business_week_mean(values):
# Filter out Saturdays
working_days = values[values.index.dayofweek != 5]
return working_days.mean()
#function to read stock data from Nepalipaisa.com api
def stock_dataFrame(stock_symbol,start_date='2020-01-01',weekly=False):
"""
input : stock_symbol
start_data set default at '2020-01-01'
weekly set default at False
output : dataframe of daily or weekly transactions
"""
#print(end_date)
today = datetime.today()
# Calculate yesterday's date
yesterday = today - timedelta(days=1)
# Format yesterday's date
formatted_yesterday = yesterday.strftime('%Y-%-m-%-d')
print(formatted_yesterday)
path = f'https://www.nepalipaisa.com/api/GetStockHistory?stockSymbol={stock_symbol}&fromDate={start_date}&toDate={formatted_yesterday}&pageNo=1&itemsPerPage=10000&pagePerDisplay=5&_=1686723457806'
df = pd.read_json(path)
theList = df['result'][0]
df = pd.DataFrame(theList)
#reversing the dataframe
df = df[::-1]
#removing 00:00:00 time
#print(type(df['tradeDate'][0]))
df['Date'] = pd.to_datetime(df['tradeDateString'])
#put date as index and remove redundant date columns
df.set_index('Date', inplace=True)
columns_to_remove = ['tradeDate', 'tradeDateString','sn']
df = df.drop(columns=columns_to_remove)
new_column_names = {'maxPrice': 'High', 'minPrice': 'Low', 'closingPrice': 'Close','volume':'Volume','previousClosing':"Open"}
df = df.rename(columns=new_column_names)
if(weekly == True):
weekly_df = df.resample('W').apply(custom_business_week_mean)
df = weekly_df
return df
import numpy as np
import pandas as pd
def create_sequences(df, window_size=5):
"""
Create input-output sequences for time series forecasting.
Parameters:
- df: pandas DataFrame with 'Close' column
- window_size: number of days to use as input (default 5)
Returns:
- X: numpy array of shape (n_samples, window_size) containing input sequences
- y: numpy array of shape (n_samples,) containing target prices
"""
close_prices = df['Close'].values
X = []
y = []
# Create sliding windows
for i in range(len(close_prices) - window_size):
# Get the window of features
window = close_prices[i:i+window_size]
X.append(window)
# Get the target (next day's close)
target = close_prices[i+window_size]
y.append(target)
return np.array(X), np.array(y)
from sklearn.preprocessing import StandardScaler
import numpy as np
def normalize_data(X, y):
"""
Normalize input sequences and target values using StandardScaler.
Parameters:
- X: Input sequences (n_samples, window_size)
- y: Target values (n_samples,)
Returns:
- X_scaled: Normalized input sequences
- y_scaled: Normalized target values
- scaler: Fitted scaler object for inverse transformation
"""
# Reshape X to 2D (n_samples * window_size, 1) for scaling
X_reshaped = X.reshape(-1, 1)
# Initialize and fit scaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_reshaped)
# Reshape back to original shape
X_scaled = X_scaled.reshape(X.shape)
# Scale target values using the same scaler
y_scaled = scaler.transform(y.reshape(-1, 1)).flatten()
return X_scaled, y_scaled, scaler
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
from sklearn.metrics import mean_absolute_percentage_error
class GRUPredictor(nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super(GRUPredictor,self).__init__()
self.gru = nn.GRU(input_size,hidden_size,batch_first=True)
self.fc = nn.Linear(hidden_size,output_size)
def forward(self,x):
_,h_n = self.gru(x)
return self.fc(h_n.squeeze(0))
# Training function with MAPE tracking
def train_model(X_train, y_train, X_test, y_test, scaler, epochs=100, batch_size=32):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Initialize model
model = GRUPredictor(1,32,1).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Create DataLoader
train_data = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=False)
# Track metrics
train_mape_history = []
test_mape_history = []
for epoch in range(epochs):
model.train()
epoch_loss = 0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# Calculate MAPE
model.eval()
with torch.no_grad():
# Training MAPE
train_pred = model(X_train.to(device))
train_pred = scaler.inverse_transform(train_pred.cpu().numpy())
train_true = scaler.inverse_transform(y_train.unsqueeze(1).cpu().numpy())
train_mape = mean_absolute_percentage_error(train_true, train_pred)
# Test MAPE
test_pred = model(X_test.to(device))
test_pred = scaler.inverse_transform(test_pred.cpu().numpy())
test_true = scaler.inverse_transform(y_test.unsqueeze(1).cpu().numpy())
test_mape = mean_absolute_percentage_error(test_true, test_pred)
train_mape_history.append(train_mape)
test_mape_history.append(test_mape)
print(f'Epoch {epoch+1}/{epochs} | Loss: {epoch_loss/len(train_loader):.4f} | '
f'Train MAPE: {train_mape:.2f}% | Test MAPE: {test_mape:.2f}%')
return model, train_mape_history, test_mape_history
train.py
Create another file, train.py. This file will use the functions of helper.py to get data and train the model. I will also register the model and the scalar of the data after training. Apart form registering models, it will also save logs and plots.
import torch
import argparse
import os
import joblib
from azureml.core import Run, Model
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from helper import stock_dataFrame,create_sequences,normalize_data,train_model
# # Get Azure ML Run context
run = Run.get_context()
# Parse hyperparameters
parser = argparse.ArgumentParser()
parser.add_argument("--symbol",type=str,default="ADBL",help="The stock symbol")
parser.add_argument("--input_size",type=int,default=1,help="input size")
parser.add_argument("--hidden_size",type=int,default=32,help="hidden size")
parser.add_argument("--output_size",type=int,default=1,help="output size")
parser.add_argument("--epochs", type=int, default=2000, help="Number of training epochs")
args = parser.parse_args()
#1. Get the data
stock_symbol = args.symbol
df = stock_dataFrame(stock_symbol,start_date='2020-01-01',weekly=False)
df.dropna(inplace=True)
X,y = create_sequences(df, window_size=5)
# 2. Normalize data
X_scaled, y_scaled, scaler = normalize_data(X, y)
# 3. Reshape for GRU (samples, timesteps, features)
X_scaled = X_scaled.reshape(X_scaled.shape[0], X_scaled.shape[1], 1)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y_scaled, test_size=0.2, shuffle=False)
# 5. Convert to PyTorch tensors
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.FloatTensor(y_test)
# 6. Train model
model, train_mape, test_mape = train_model(X_train, y_train, X_test, y_test, scaler, epochs=100, batch_size=32)
print("Train_MAPE",sum(train_mape)/len(train_mape))
print("Test_MAPE",sum(test_mape)/len(test_mape))
run.log("Train_MAPE",sum(train_mape)/len(train_mape))
run.log("Test_MAPE",sum(test_mape)/len(test_mape))
# 7. save model
os.makedirs("outputs",exist_ok=True)
model_path = "outputs/pytorch_gru.pth"
# torch.save(model,model_path)
torch.save(model.state_dict(),model_path)
print(f"Model saved in {model_path}")
# #register model
Model.register(
workspace=run.experiment.workspace,
model_name="pytorch_gru",
model_path = model_path,
description="adbl trained on new gru"
)
print("Model registered successfully")
# 8. Save scaler
scaler_path = "outputs/scaler.save"
joblib.dump(scaler, scaler_path)
print(f"Scaler saved at {scaler_path}")
# Register scaler
Model.register(
workspace=run.experiment.workspace,
model_name="scaler",
model_path=scaler_path,
description="Scaler used for ADBL GRU model"
)
print("Scaler registered successfully")
# 7. Plot results
plt.figure(figsize=(10, 5))
plt.plot(train_mape, label='Train MAPE')
plt.plot(test_mape, label='Test MAPE')
plt.title('MAPE Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('MAPE (%)')
plt.legend()
plt.show()
# Save the plot to a file
plot_path = "LOSS.png"
plt.savefig(plot_path)
plt.close()
# Log the plot to Azure ML
run.log_image('LOSS PLOT', plot_path)
# 9. Predict on test set
model.eval()
with torch.no_grad():
y_pred = model(X_test).squeeze().numpy()
y_true = y_test.squeeze().numpy()
# 10. Inverse scale predictions and true values
y_pred_inv = scaler.inverse_transform(y_pred.reshape(-1, 1)).flatten()
y_test_inv = scaler.inverse_transform(y_true.reshape(-1, 1)).flatten()
# 11. Plot predictions vs true values
plt.figure(figsize=(12, 6))
plt.plot(y_test_inv, label="Actual", linewidth=2)
plt.plot(y_pred_inv, label="Predicted", linestyle='--')
plt.title(f"{stock_symbol} Price Prediction (Test Set)")
plt.xlabel("Time Step")
plt.ylabel("Price")
plt.legend()
prediction_plot_path = "outputs/prediction_vs_actual.png"
plt.savefig(prediction_plot_path)
plt.close()
print(f"Prediction plot saved at {prediction_plot_path}")
# Log prediction plot to Azure ML
run.log_image("Prediction vs Actual", prediction_plot_path)
# Complete run
run.complete()environment.yml
Now, create a file named environment.yml
name: pytorch-env
dependencies:
- python=3.10
- pytorch=2.1.0
- scikit-learn
- pip
- pip:
- azureml-sdk
- mlflow
- numpy
- matplotlib
- pandasThis files defines a reproducible environment for training and deploying machine learning models – in this case, using the PyTorch and Azure ML.
This files specifies the conda environment configuration that Azure ML (or local tools like conda) can use to:
- Recreate a consistent environment across training, testing and deployment.
- Package and deploy your model in a container with all the dependencies it needs.
It ensures portability, reproducibility and compatibility – core principles of MLops.
- name: pytorch-env
- This gives the environment a name. We can refer to this name when activating or referencing it within Azure ML or locally.
- depencencies:
- This section lists everything the environment need to function, like python, pytorch, scikit-learn, pip.
- pip:
- This sublist includes Python Packages that will be installed via pip.
Conda first installs the core environments (Python, Pytorch, scikit-learn), then pip installs additional packages into the environment. Azure ML builds this in order, ensuring dependencies do not clash.
Create, train, save and register
run.ipynb
from azureml.core import Workspace, Experiment, ScriptRunConfig, Environment
# Connect to Azure ML Workspace
ws = Workspace.from_config() # Ensure your `config.json` file is present
# Create an Azure ML experiment
experiment = Experiment(ws, "Pytorch-NN-GRU")
# Define an execution environment
env = Environment.from_conda_specification(name="pytorch-env", file_path="environment.yml")Above code connects to the Azure ML Workspace, create an Azure ML experiment and an execution environment with the help of “environment.yml” file.
from azureml.core.compute import ComputeInstance, ComputeTarget
from azureml.exceptions import ComputeTargetException
# Define compute instance name
compute_name = "compute-A"
# Set VM size (adjust as needed)
vm_size = "Standard_D2_v3"
try:
# Check if the compute instance already exists
compute_instance = ComputeInstance(ws, compute_name)
print(f"Compute instance {compute_name} already exists.")
except ComputeTargetException:
print(f"Creating new compute instance: {compute_name}")
compute_config = ComputeInstance.provisioning_configuration(vm_size=vm_size)
compute_instance = ComputeInstance.create(ws, compute_name, compute_config)
compute_instance.wait_for_completion(show_output=True)
print(f"Compute instance '{compute_name}' is ready!")This creates a new compute instance in your Azure with compute name “compute-A42”.
# Set up the script configuration
compute_name = "compute-A"
script_config = ScriptRunConfig(
source_directory=".", # Path to the script folder
script="train.py",
compute_target=compute_name, # Change to your Azure ML compute name
environment=env,
arguments=["--symbol","ADBL"]
)This script sets up a training job using Azure ML’s ScriptRunConfig.
It specifies the script location (train.py), compute target (compute-A42), and environment (env).
Custom arguments like stock symbol, model parameters, and epochs are passed in.
This configuration is used to submit and run training remotely on Azure.
# Submit experiment
run = experiment.submit(script_config)
print("Experiment submitted! Tracking in Azure ML Studio.")
run.wait_for_completion(show_output=True)This code submits the training job to Azure ML for execution.
It tracks the run under the specified experiment and provides a live output of training progress.run.wait_for_completion(show_output=True) blocks the script until the run finishes.
You can monitor the run details, logs, and metrics in Azure ML Studio.
Check Azure
Go to home page of your Azure ML studio. On left under assets you will find jobs, models etc.
Let’s check jobs.
Click on the latest job or the job just completed.
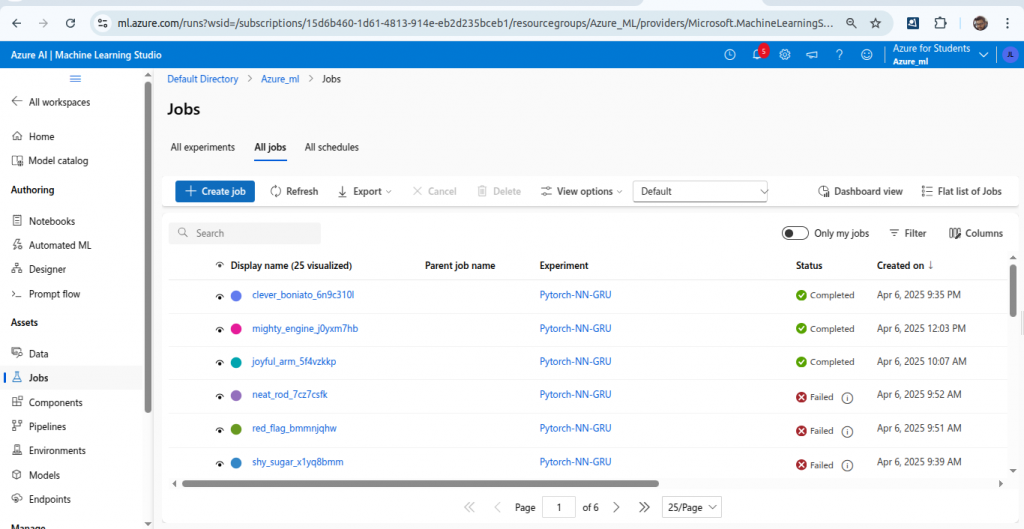
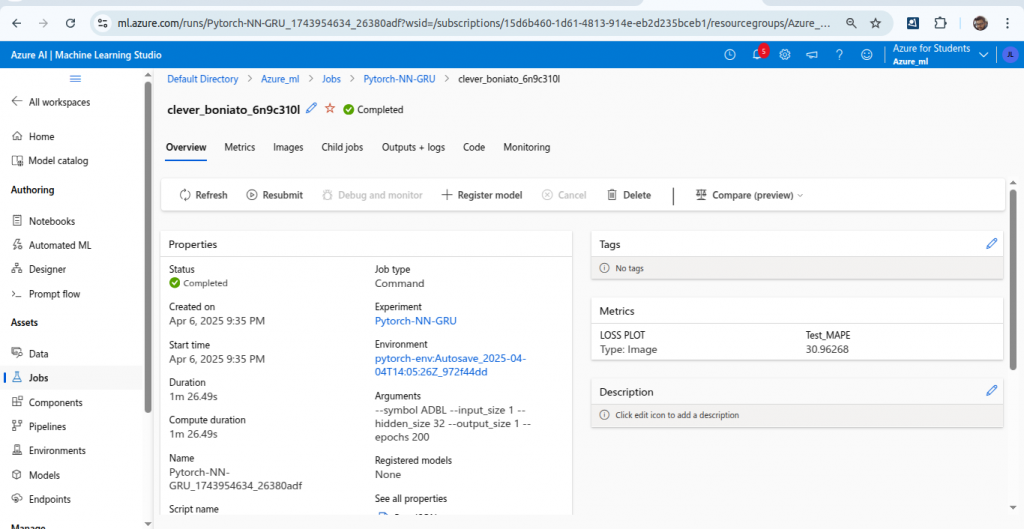
You can check metrics, images and others.
Now, again from left, select models.
You will see your model and scalar. Code to register both models and scaler along with the metrics and images were written in train.py
Now, after training the model and registering it successfully, we will deploy it.
Deployment
score.py
score.py is what lets your model work in production. It tells Azure ML how to use your model once it’s deployed—making it a core piece of any ML deployment pipeline.
import json
import torch
import torch.nn as nn
import numpy as np
import os
import joblib
from azureml.core.model import Model
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
_, h_n = self.gru(x)
return self.fc(h_n.squeeze(0))
# Global model and scaler objects
model = None
scaler = None
def init():
global model, scaler
# Load GRU model
model_path = Model.get_model_path("pytorch_gru")
model = GRUModel(input_size=1, hidden_size=32, output_size=1)
model.load_state_dict(torch.load(model_path, map_location=torch.device("cpu")))
model.eval()
# Load scaler
scaler_path = Model.get_model_path("scaler")
scaler = joblib.load(scaler_path)
def run(raw_data):
try:
print("Received raw data:", raw_data) # Debugging
data = json.loads(raw_data)
inputs = data["data"] # expects [[val1, val2, val3, val4, val5], ...]
# Ensure all sequences have exactly 5 timesteps
for seq in inputs:
if len(seq) != 5:
return {"error": "Each input sequence must have exactly 5 timesteps."}
# Convert to numpy array and reshape for scaling
inputs_np = np.array(inputs, dtype=np.float32).reshape(-1, 1)
print("Reshaped input array for scaling:", inputs_np.shape) # Debugging
# Apply scaling
inputs_scaled = scaler.transform(inputs_np)
print("Scaled inputs:", inputs_scaled.shape) # Debugging
# Reshape back to (batch_size, 5, 1)
batch_size = len(inputs)
x = torch.tensor(inputs_scaled.reshape(batch_size, 5, 1), dtype=torch.float32)
print("Final tensor shape for model:", x.shape) # Debugging
with torch.no_grad():
predictions = model(x)
# Convert predictions back to numpy
preds_np = predictions.numpy().reshape(-1, 1)
print("Raw model predictions:", preds_np) # Debugging
# Apply inverse transformation
preds_inversed = scaler.inverse_transform(preds_np)
print("Inverse-scaled predictions:", preds_inversed) # Debugging
return preds_inversed.flatten().tolist()
except Exception as e:
print("Error occurred:", str(e)) # Debugging
return {"error": str(e)}
Azure ML endpoints call score.py when receiving a prediction request.
It contains two required functions:
init()– loads your model and any necessary artifacts (e.g., scalers).run()– takes incoming data, runs inference, and returns the result.
deployment.ipynb
from azureml.core import Environment
env = Environment(name="azure_pytorch_env")
env.python.conda_dependencies.add_pip_package("torch==2.1.0")
env.python.conda_dependencies.add_pip_package("numpy")
env.python.conda_dependencies.add_pip_package("scikit-learn")This code creates a custom Azure ML environment named "azure_pytorch_env" and installs PyTorch 2.1.0, NumPy, and scikit-learn via pip. It’s used to ensure consistent dependencies during model training and deployment.
from azureml.core import Workspace, Model
from azureml.core.webservice import AciWebservice
from azureml.core.model import InferenceConfig
# Connect to Azure ML Workspace
ws = Workspace.from_config()
# Load registered model and scaler
model = Model(ws, "pytorch_nn_gru")
scaler = Model(ws, "adbl_scaler")
# Define inference configuration
inference_config = InferenceConfig(
entry_script="score.py",
environment=env
)
# Define deployment configuration (ACI)
deployment_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1)
# Deploy both the model and scaler
service = Model.deploy(
workspace=ws,
name="pytorch-n-gru-scalar",
models=[model, scaler], # <-- Include both
inference_config=inference_config,
deployment_config=deployment_config
)
service.wait_for_deployment(show_output=True)
# Print Scoring URI
print(f"Deployment successful! Scoring URI: {service.scoring_uri}")
- Connect to Workspace & Load Models:
Connects to Azure ML workspace using config file.
Loads both the GRU model and the corresponding scaler registered in Azure. - Define Inference Configuration:
Specifies thescore.pyscript for inference logic.
Defines the environment with necessary packages for deployment. - Define Deployment Configuration:
Sets up deployment target as Azure Container Instance (ACI).
Allocates 1 CPU core and 1GB memory for the deployed service. - Deploy the Model & Scaler:
Deploys both model and scaler together as a web service.
Waits for deployment completion and displays output logs. - Output the Scoring URI:
Prints the URI endpoint to interact with the deployed model.
This URI is used by applications (like Flask) to send requests.
After completion of this, you can see your endpoint in Azure ML.
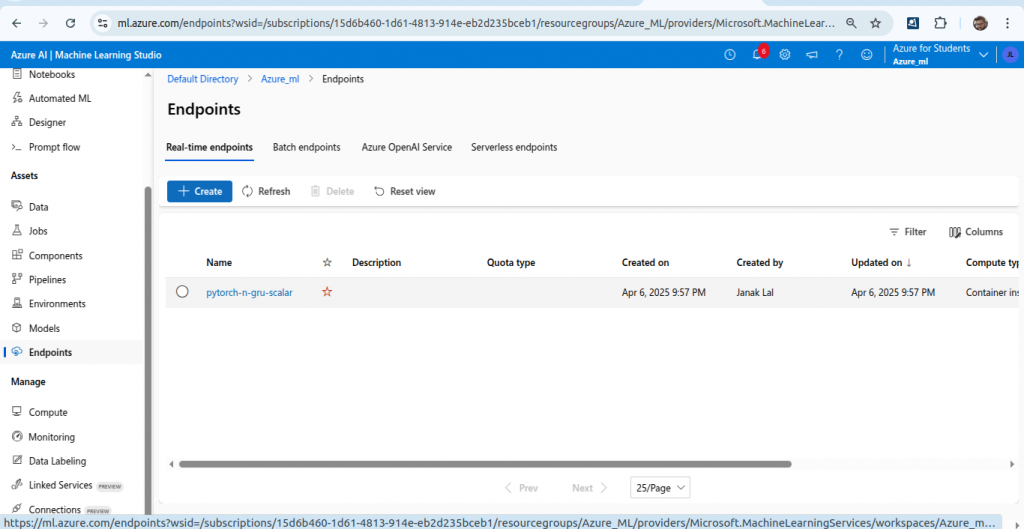
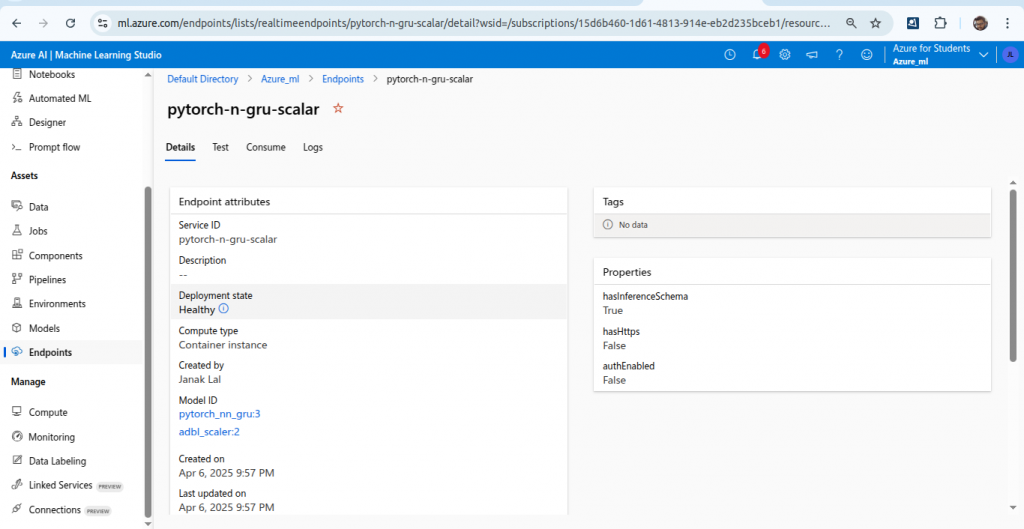
Test the deployed endpoint with the following code.
import requests
import json
# Select a sample (first one for testing)
sample_input = [[0.1, 0.2, 0.3, 0.4, 0.5],
[700, 705, 708, 715, 719]]
# Define the input JSON payload
payload = json.dumps({"data": sample_input})
# Get the deployment endpoint
scoring_uri = service.scoring_uri
headers = {"Content-Type": "application/json"}
# Send request to the deployed model
response = requests.post(scoring_uri, data=payload, headers=headers)
# Print response
print("Response:", response.json())Output
Response: [74.09484100341797, 673.948974609375]
Conclusion
In this part we learnt to train, register and deploy our model. In next part, we will learn how to create a flask web application which will use this endpoint to forecast the stock price.
You can find all the codes in github.